最佳首次搜索(知情搜索)
原文:https://www . geesforgeks . org/best-first-search-informed-search/
先决条件: BFS 、 DFS 在 BFS 和 DFS 中,当我们在一个节点时,我们可以考虑相邻的任何一个作为下一个节点。因此,BFS 和 DFS 都在不考虑任何成本函数的情况下盲目探索路径。最佳优先搜索的思想是使用一个评估函数来决定哪个相邻的最有希望,然后进行探索。最佳首次搜索属于启发式搜索或通知搜索的范畴。
我们使用优先级队列来存储节点的开销。所以这个实现是 BFS 的一个变体,我们只需要把 Queue 改成 PriorityQueue。
// This pseudocode is adapted from below
// source:
// https://courses.cs.washington.edu/
Best-First-Search(Graph g, Node start)
1) Create an empty PriorityQueue
PriorityQueue pq;
2) Insert "start" in pq.
pq.insert(start)
3) Until PriorityQueue is empty
u = PriorityQueue.DeleteMin
If u is the goal
Exit
Else
Foreach neighbor v of u
If v "Unvisited"
Mark v "Visited"
pq.insert(v)
Mark u "Examined"
End procedure
让我们考虑下面的例子。
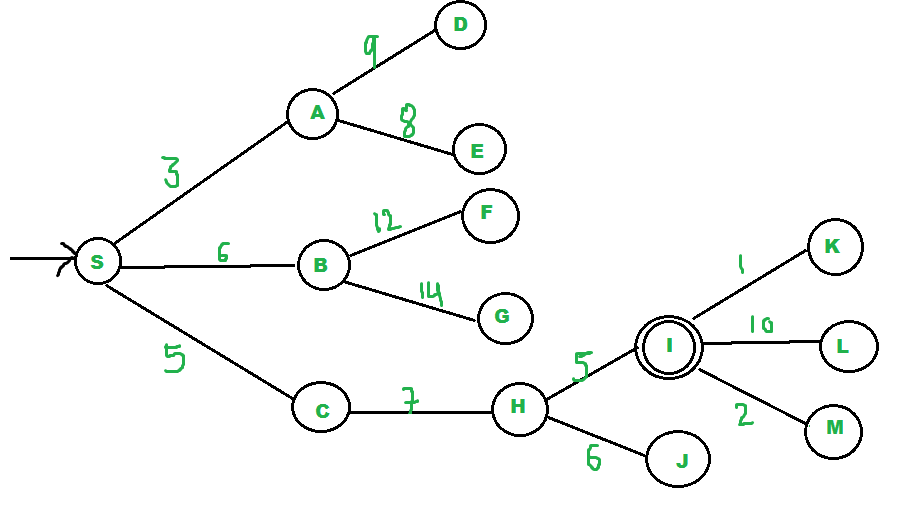
We start from source "S" and search for
goal "I" using given costs and Best
First search.
pq initially contains S
We remove s from and process unvisited
neighbors of S to pq.
pq now contains {A, C, B} (C is put
before B because C has lesser cost)
We remove A from pq and process unvisited
neighbors of A to pq.
pq now contains {C, B, E, D}
We remove C from pq and process unvisited
neighbors of C to pq.
pq now contains {B, H, E, D}
We remove B from pq and process unvisited
neighbors of B to pq.
pq now contains {H, E, D, F, G}
We remove H from pq. Since our goal
"I" is a neighbor of H, we return.
下面是上述想法的实现:
C++
// C++ program to implement Best First Search using priority
// queue
#include <bits/stdc++.h>
using namespace std;
typedef pair<int, int> pi;
vector<vector<pi> > graph;
// Function for adding edges to graph
void addedge(int x, int y, int cost)
{
graph[x].push_back(make_pair(cost, y));
graph[y].push_back(make_pair(cost, x));
}
// Function For Implementing Best First Search
// Gives output path having lowest cost
void best_first_search(int source, int target, int n)
{
vector<bool> visited(n, false);
// MIN HEAP priority queue
priority_queue<pi, vector<pi>, greater<pi> > pq;
// sorting in pq gets done by first value of pair
pq.push(make_pair(0, source));
int s = source;
visited[s] = true;
while (!pq.empty()) {
int x = pq.top().second;
// Displaying the path having lowest cost
cout << x << " ";
pq.pop();
if (x == target)
break;
for (int i = 0; i < graph[x].size(); i++) {
if (!visited[graph[x][i].second]) {
visited[graph[x][i].second] = true;
pq.push(make_pair(graph[x][i].first,graph[x][i].second));
}
}
}
}
// Driver code to test above methods
int main()
{
// No. of Nodes
int v = 14;
graph.resize(v);
// The nodes shown in above example(by alphabets) are
// implemented using integers addedge(x,y,cost);
addedge(0, 1, 3);
addedge(0, 2, 6);
addedge(0, 3, 5);
addedge(1, 4, 9);
addedge(1, 5, 8);
addedge(2, 6, 12);
addedge(2, 7, 14);
addedge(3, 8, 7);
addedge(8, 9, 5);
addedge(8, 10, 6);
addedge(9, 11, 1);
addedge(9, 12, 10);
addedge(9, 13, 2);
int source = 0;
int target = 9;
// Function call
best_first_search(source, target, v);
return 0;
}
计算机编程语言
from queue import PriorityQueue
v = 14
graph = [[] for i in range(v)]
# Function For Implementing Best First Search
# Gives output path having lowest cost
def best_first_search(source, target, n):
visited = [0] * n
visited = True
pq = PriorityQueue()
pq.put((0, source))
while pq.empty() == False:
u = pq.get()[1]
# Displaying the path having lowest cost
print(u, end=" ")
if u == target:
break
for v, c in graph[u]:
if visited[v] == False:
visited[v] = True
pq.put((c, v))
print()
# Function for adding edges to graph
def addedge(x, y, cost):
graph[x].append((y, cost))
graph[y].append((x, cost))
# The nodes shown in above example(by alphabets) are
# implemented using integers addedge(x,y,cost);
addedge(0, 1, 3)
addedge(0, 2, 6)
addedge(0, 3, 5)
addedge(1, 4, 9)
addedge(1, 5, 8)
addedge(2, 6, 12)
addedge(2, 7, 14)
addedge(3, 8, 7)
addedge(8, 9, 5)
addedge(8, 10, 6)
addedge(9, 11, 1)
addedge(9, 12, 10)
addedge(9, 13, 2)
source = 0
target = 9
best_first_search(source, target, v)
# This code is contributed by Jyotheeswar Ganne
Output
0 1 3 2 8 9
分析:
- 最佳优先搜索的最坏情况时间复杂度为 O(n * Log n),其中 n 为节点数。在最坏的情况下,我们可能必须访问所有节点才能达到目标。请注意,优先级队列是使用最小(或最大)堆实现的,插入和移除操作需要 O(log n)时间。
- 算法的性能取决于成本或评估函数的设计。
相关文章: A*搜索算法 本文由香巴拉维辛格供稿。如果你喜欢 GeeksforGeeks 并想投稿,你也可以用write.geeksforgeeks.org写一篇文章或者把你的文章邮寄到 review-team@geeksforgeeks.org。看到你的文章出现在极客博客主页上,帮助其他极客。
如果你发现任何不正确的地方,或者你想分享更多关于上面讨论的话题的信息,请写评论。
版权属于:月萌API www.moonapi.com,转载请注明出处
