- 热门标签
全部
- 全部
- 共享
- 商用
全部
- 全部
- 月萌API
- 第三方
-

焊接缺陷是指焊接零件表面出现不规则、不连续的现象。焊接接头的缺陷可能会导致组件报废、维修成本高昂,在工作条件下的组件的性能显着下降,在极端情况下还会导致灾难性故障,并造成财产和生命损失。此外,由于焊接技术固有的弱点和金属特性,在焊接中总是存在某些缺陷。不可能获得完美的焊接,因此评估焊接质量非常重要。 可以通过图像来检测焊接中的缺陷,并精确测量每个缺陷的严重性,这将有助于并避免上述危险情况的出现。使用卷积神经网络算法和U-Net架构可提高检测的效率,精度也能达到98.3%。 供应商:缺陷检测论文验证超大训练集 -

Office-Home 是一个用于域适应的基准数据集,它包含 4 个域,每个域由 65 个类别组成。这四个领域是: 艺术——素描、绘画、装饰等形式的艺术形象;剪贴画——剪贴画图像的集合;产品——没有背景的物体图像;和真实世界——用普通相机拍摄的物体图像。它包含 15,500 张图像,平均每个类大约 70 张图像,一个类最多 99 张图像。
供应商:Moonapi优质数据集论文常用数据集数据集大小 1077.57 MB -

“德国交通标志识别基准”是在 2011 年国际神经网络联合会议 (IJCNN) 上举办的多类单图像分类挑战赛。交通标志的自动识别是高级驾驶辅助系统所必需的,并且构成了具有挑战性的现实世界计算机视觉和模式识别问题。该数据集收集了超过 50,000 个交通标志图像的全面、逼真的数据集。它反映了由于距离、照明、天气条件、部分遮挡和旋转而导致的标志视觉外观的强烈变化。这些图像由几个预先计算的特征集补充,以
供应商:Moonapi优质数据集论文常用数据集数据集大小 611.85 MB -
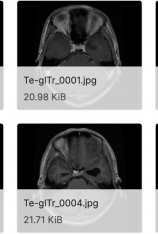
该数据集包含7022张人脑 MRI 图像,分为 4 类:胶质瘤-脑膜瘤-无肿瘤和垂体。注意这个数据集中的图像大小是不同的。可以在预处理并去除多余的边距后将图像调整为所需的大小。
供应商:Moonapi优质数据集论文常用数据集数据集大小 147.92 MB -
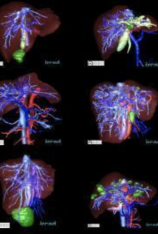
3D-IRCADb-01 数据库由 10 名女性和 10 名男性 75% 的肝肿瘤患者的 3D CT 扫描组成。 20个文件夹对应20个不同的患者,可以单独下载也可以联合下载。下表提供了图像信息,例如肝脏大小(宽度、深度、高度)或根据 Couninaud 分割的肿瘤位置。它还表明肝脏分割软件可能遇到的主要困难是由于与邻近器官的接触、肝脏的非典型形状或密度,甚至图像中的伪影。 For refer
供应商:Moonapi优质数据集论文常用数据集数据集大小 880.73 MB -
数据集介绍 该数据集包含在大学礼堂中从三个垂直安装的 Kinect 传感器获取的 3000 多个 RGB-D 帧。数据主要包含从不同方向和不同遮挡程度看到的直立行走和站立的人。 Annotation Format: Each annotated track is defined in a file named as TRACK000N.DAT . The file describes the
供应商:Moonapi优质数据集论文常用数据集数据集大小 2673.92 MB -

该数据集提供通过 CARLA 自动驾驶汽车模拟器捕获的数据图像和标记语义分割。 这些数据是作为 Lyft Udacity Challenge 的一部分生成的。 该数据集可用于训练 ML 算法以识别图像中汽车、道路等的语义分割。 数据有5组1000张图片和对应的标签。
供应商:Moonapi优质数据集论文常用数据集数据集大小 5231.48 MB -

Description有的 Earth Vision 数据集要么适用于语义分割,要么适用于对象检测。 iSAID 是第一个用于航空图像实例分割的基准数据集。这个大规模和密集注释的数据集包含 2,806 张高分辨率图像的 15 个类别的 655,451 个对象实例。 iSAID 的显着特征如下:(a) 大量具有高空间分辨率的图像,(b) 十五个重要且常见的类别,(c) 每个类别的大量实例,(d) 每
供应商:Moonapi优质数据集论文常用数据集数据集大小 274.92 MB


