官方问题反馈



API接口问题反馈
-

DriveSeg场景分割数据集
0 话题我们提供了 MIT DriveSeg 数据集,这是一个大规模的驾驶场景分割数据集,为 5,000 个视频帧中的每个像素和每个像素都进行了密集注释。这个数据集是一个面向前的逐帧像素级语义标记数据集,该数据集是在连续白天驾驶通过拥挤的城市街道时从移动的车辆捕获的。该数据集的目的是允许探索时间动态信息的价值,以便在动态的真实操作环境中进行全场景分割。创建时间: 2022-11-17 00:17 -

CamSeq 2007数据集
0 话题CamSeq是一个地面数据集,可自由用于视频目标识别中的研究工作。该数据集包含 101 个 960x720 像素的图像对。 每个掩码都由文件名之外的“_L”指定。 所有图像(原始图像和真实图像)均为未压缩的 24 位彩色 PNG 格式。 该数据集最初是针对自动驾驶汽车的问题而设计的。此序列描绘了从一辆动感的汽车拍摄的剑桥市的动感驾驶场景。这是一个具有挑战性的数据集,因为除了汽车的自我运动之外,其他创建时间: 2022-11-17 00:17 -

驾驶模拟器车道检测数据集
0 话题该数据集由 Carla 驾驶模拟器生成的图像组成。 训练图像是由安装在模拟车辆中的行车记录仪捕获的图像。 标签图像是分割掩码。 标签图像将每个像素分类为:左侧车道边界的和右侧车道边界。与该数据集相关的挑战是训练一个能够准确预测验证数据集的分割掩码的模型。创建时间: 2022-11-17 00:17 -

道路上自动驾驶汽车数据集
0 话题该数据集为自动驾驶车辆提供了易于使用的训练数据。 提供驾驶视频中每一帧对应的转向角、加速度、刹车和档位。 这段视频是使用安装在汽车挡风玻璃上的摄像头录制的,该汽车沿着印度喀拉拉邦的道路行驶。创建时间: 2022-11-17 00:17 -

CUlane数据集
0 话题CULane 是一个大规模的具有挑战性的数据集,用于交通车道检测的学术研究。 它是由安装在北京不同司机驾驶的六辆不同车辆上的摄像头收集的。 收集了超过 55 小时的视频,提取了 133,235 帧。 在每一帧中,交通车道都用三次样条手动注释。 对于车道标记被车辆遮挡或看不见的情况,仍根据上下文进行车道注释。 障碍物另一侧的车道没有注释。 在这个数据集中,主要关注的是四车道标记的检测,这在实际应用中创建时间: 2022-11-17 00:17 -

非洲地区交通标志数据集
0 话题该数据集已特别针对非洲地区进行了改进。 两个开源数据集仅用于提取非洲地区使用的交通标志。该数据集包含来自所有类别的 76 个类,例如 监管、警告、指南和信息标志。 该数据集总共包含 19,346 张图像和每个类别至少 200 个实例。创建时间: 2022-11-17 00:17 -

Argoverse数据集
0 话题Argoverse针对的任务:3D追踪和动作预测,两个任务对应的数据集其实是独立的,只是采集设备和采集地点一样而已。提供了360度的视频和点云信息,并根据点云重建了地图,全天候全光照。标注了视频和点云中的3D bounding box。3D追踪的数据集包含113段15-30秒的视频,动作预测中包含323,557段5秒的视频(总计320小时)。数据集的主要亮点还是在原始数据和地图的联动上。创建时间: 2022-11-17 00:17 -

BDD100K驾驶视频数据集
0 话题UCB的全天候全光照大型数据集,包含1,100小时的HD录像、GPS/IMU、时间戳信息,100,000张图片的2D bounding box标注,10,000张图片的语义分割和实例分割标注、驾驶决策标注和路况标注。官方推荐使用此数据集的十个自动驾驶任务:图像标注、道路检测、可行驶区域分割、交通参与物检测、语义分割、实例分割、多物体检测追踪、多物体分割追踪、域适应和模仿学习。创建时间: 2022-11-17 00:17 -

自动驾驶汽车的语义分割数据集
0 话题该数据集提供通过 CARLA 自动驾驶汽车模拟器捕获的数据图像和标记语义分割。 这些数据是作为 Lyft Udacity Challenge 的一部分生成的。 该数据集可用于训练 ML 算法以识别图像中汽车、道路等的语义分割。 数据有5组1000张图片和对应的标签。创建时间: 2022-11-17 00:16 -
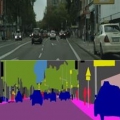
城市景观图像对数据集
0 话题城市景观数据(数据集主页)包含从德国驾驶的车辆中拍摄的标记视频。此版本是作为 Pix2Pix 论文的一部分创建的已处理子样本。数据集包含来自原始视频的静止图像,语义分割标签与原始图像一起显示在图像中。这是语义分割任务的最佳数据集之一。 该数据集有 2975 个训练图像文件和 500 个验证图像文件。 每个图像文件为 256x512 像素,每个文件是与图像左半部分的原始照片以及右半部分的标记图像创建时间: 2022-11-17 00:16
