官方问题反馈



API接口问题反馈
-

幸福畅销书评论数据集
0 话题自 2005 年以来,整体幸福感正在下降,而悲伤和愤怒等负面情绪却在上升。更糟糕的是,越来越多的年轻人患有精神疾病、成瘾及其后果。在某种程度上,这是可以理解的。如今,在世界上发生的一切事情中,很难在精神上维持生计。难怪我们可以解决最轻微的问题。但是我们会因为不知道如何处理这一切而感到难过,并且会更深地陷入不快乐。本数据集收集了排名前33名的关于幸福的书籍、评论和引用。创建时间: 2022-11-17 00:13 -

Twitter 情绪推文数据集
0 话题数据集介绍: Twitter 是一个在线社交媒体平台,人们在其中以推文的形式分享他们的想法。据观察,有些人滥用它来发布仇恨内容。Twitter 正试图解决这个问题,我们将通过创建一个强大的基于 NLP 的分类器模型来帮助它来区分负面推文并阻止此类推文。你能建立一个强大的分类器模型来预测吗?每行包含一条推文的文本和一个情绪标签。在训练集中,您将获得一个从推文 (selected_text) 中提取的创建时间: 2022-11-17 00:13 -
电影元数据
0 话题这些文件包含 TMDB 数据集中列出的超过 700,000 部电影的元数据。数据集每天更新以确保更新电影数据集。数据点包括演员、工作人员、情节关键词、预算、收入、海报、发布日期、语言、制作公司、国家、TMDB 投票计数和投票平均值、评论、推荐。 您可以使用此数据集执行的一些操作: 构建基于内容和基于协作过滤的推荐引擎。 根据某个指标预测电影收入和/或电影成功。 哪些电影往往在 TMDB 上获创建时间: 2022-11-17 00:13 -

-
印度新闻头条数据集
0 话题该新闻数据集是印度次大陆从 2001 年初到 2022 年第一季度的重要事件的持久历史档案,由印度记者实时记录。它包含印度时报发布的大约 360 万个事件。 大部分数据集中在印度地方新闻,包括国家、城市和娱乐。 由Rohit Kulkarni编写创建时间: 2022-11-17 00:13 -
Twitter地理定位信息数据集
0 话题该数据集是与学术项目协调使用的公共推特更新的集合,用于研究与推特相关的地理定位数据。训练集包含 115,886 个 Twitter 用户和来自用户的 3,844,612 个更新。用户的所有位置都在美国以城市级粒度进行自我标记。测试集包含 5,136 个 Twitter 用户和来自用户的 5,156,047 条推文。用户的所有位置都是从他们的智能手机以“UT:纬度,经度”的形式上传的。 Plea创建时间: 2022-11-16 23:13 -
CASIA手写数据集
0 话题CASIA-HWDB-T包括56,469个二字或多字触摸字符串,其中1,818个字符串有多个触摸字符。 作者还将接触字符串划分为 50,157 个全中文字符串、2,788 个全数字字符串、328 个全字母字符串和 3,196 个混合字符字符串。 所有的字符串都标注了字符类、触摸点的位置以及字符串高度和平均笔画宽度等辅助值。 Publication: Liang Xu, Fei Yin, Qiu创建时间: 2022-11-16 23:13 -

m2caiSeg腹腔镜图像数据集
0 话题m2caiSeg是根据真实世界外科手术的内窥镜视频源创建的。数据由 307 张图像组成,每张图像都针对场景中存在的器官和不同的手术器械进行了注释。 If you use this dataset in your work, kindly do cite our paper: @article{maqbool2020m2caiseg, title={m2caiSeg: Semantic Se创建时间: 2022-11-16 23:13 -
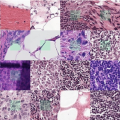
淋巴结切片的组织病理学数据集
0 话题PatchCamelyon 是一个新的且具有挑战性的图像分类数据集。它由从淋巴结切片的组织病理学扫描中提取的 327.680 张彩色图像 (96 x 96px) 组成。每个图像都带有一个二进制标签,表示存在转移组织。PCam 为机器学习模型提供了新的基准:大于 CIFAR10,小于 imagenet,可在单个 GPU 上训练。 Usage and Tips Keras Example Gene创建时间: 2022-11-16 23:13 -
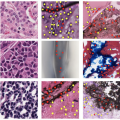
PanNuke癌组织细胞数据集
0 话题半自动生成的细胞核实例分割和分类数据集,包含 19 种不同组织类型的详尽细胞核标签。该数据集由 481 个视野组成,其中 312 个视野是从多个数据源的 20K 多个不同放大倍率的整张幻灯片图像中随机采样的。该数据集总共包含 205,343 个标记的核,每个核都有一个实例分割掩码。在 pannuke 上训练的模型可以帮助整个幻灯片图像组织类型分割,并推广到新组织。PanNuke 演示了首批成功半自创建时间: 2022-11-16 23:13
