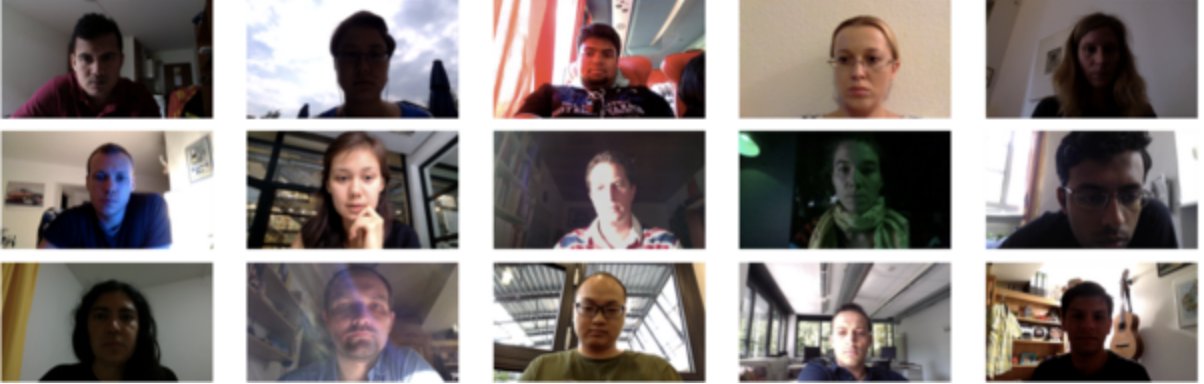
MPIIGaze数据集
订阅方案:
普通用户:¥30.00
VIP用户:¥0.00
联系客服
查看订阅方案
数据集简介:
展开
数据集介绍: 基于外观的凝视估计被认为在现实环境中很有效,但现有数据集是在受控实验室条件下收集的,并且没有对多个数据集的方法进行评估。在这项工作中,我们研究了野外基于外表的凝视估计。我们展示了MPIIGaze数据集,其中包含我们在三个多月的日常笔记本电脑使用过程中从15名参与者收集的213659张图像。在外观和照明方面,我们的数据集比现有的数据集变化更大。我们还提出了一种使用多模式卷积神经网络进行
-
MPIIGaze数据集简介
数据集介绍:
基于外观的凝视估计被认为在现实环境中很有效,但现有数据集是在受控实验室条件下收集的,并且没有对多个数据集的方法进行评估。在这项工作中,我们研究了野外基于外表的凝视估计。我们展示了MPIIGaze数据集,其中包含我们在三个多月的日常笔记本电脑使用过程中从15名参与者收集的213659张图像。在外观和照明方面,我们的数据集比现有的数据集变化更大。我们还提出了一种使用多模式卷积神经网络进行基于野生外观的凝视估计的方法,该方法在最具挑战性的跨数据集评估中显著优于最先进的方法。我们对三个当前数据集(包括我们自己的数据集)上的几种最先进的基于图像的凝视估计算法进行了广泛评估。这一评估提供了清晰的见解,并使我们能够确定野外凝视评估的关键研究挑战。
If you use this dataset in scientific publication, please cite the following paper:
-
Appearance-based Gaze Estimation in the Wild, X. Zhang, Y. Sugano, M. Fritz and A. Bulling, Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June, p.4511-4520, (2015).
arXiv, PDF -
@inproceedings{zhang15_cvpr,
Author = {Xucong Zhang and Yusuke Sugano and Mario Fritz and Bulling, Andreas},
Title = {Appearance-based Gaze Estimation in the Wild},
Booktitle = {Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
Year = {2015},
Month = {June}
Pages = {4511-4520} }
MPIIGaze is a dataset for appearance-based gaze estimation in the wild. It contains 213,659 images collected from 15 participants during natural everyday laptop use over more than three months. It has a large variability in appearance and illumination.
GitHub is where over 94 million developers shape the future of software, together. Contribute to the open source community, manage your Git repositories, review code like a pro, track bugs and features, power your CI/CD and DevOps workflows, and secure code before you commit it.
The most popular research, guides, news and more in artificial intelligence
PubMed® comprises more than 34 million citations for biomedical literature from MEDLINE, life science journals, and online books. Citations may include links to full text content from PubMed Central and publisher web sites.
这篇文章主要介绍MPIIGaze: Real-World Dataset and Deep Appearance-Based Gaze Estimation这篇论文实现3d gaze vector的细节。主要贡献我觉得这篇论文最大贡献就是公开了Gaze数据集, 这个数据集包含213,659 张…
已完结: T骨牛排:视线估计(Gaze Estimation)简介(一)-概述T骨牛排:视线估计(Gaze Estimation)简介(二)-注视目标估计T骨牛排:视线估计(Gaze Estimation)简介(三)-注视点估计T骨牛排:视线估计(Gaze Estimation)…
[TOC] 前言 简介 在使用神经网络解决Gaze Estimation的问题上, "Appearance Based Gaze Estimation in the Wild" 是
MPII Gaze 网络结构
这个网络的输入是眼睛图片和headpose(图中的h), 注意图片经过13层卷积操作后flatten后与headpose数据concate,然后回归成gaze vector, 这里使用的headpose是归一化坐标系下的pitch和yaw, 输出的gaze vector本来应该是一个3维向量, 这里用极坐标表示只剩下两个值pitch和yaw。MPIIGaze:真实数据集和基于深度外观的注视估计
据信,基于学习的方法对于无约束的凝视估计(即来自单眼RGB摄像机的凝视估计,无需用户,环境或摄像机的假设)非常有效。但是,当前的凝视数据集是在实验室条件下收集的,并且未在多个数据集之间评估方法。我们的工作为解决这些局限性做出了三点贡献。首先,我们展示了MPIIGaze数据集,其中包含213,659张全脸图像以及在几个月的笔记本电脑日常使用中从15个用户那里收集的相应的地面注视位置。经验采样方法可确保连续注视和头部姿势,以及眼睛外观和照度的实际变化。为了便于进行跨数据集评估,对37,667张图像进行了手动注解,包括眼角,嘴角和瞳孔中心。其次,我们对包括MPIIGaze在内的三个当前数据集进行了最先进的注视估计方法的广泛评估。我们研究了关键挑战,包括目标注视范围,照明条件和面部外观变化。我们显示图像分辨率和两只眼睛的使用都会影响凝视估计性能,而头部姿势和瞳孔中心信息的信息量较少。最后,我们提出了GazeNet,这是第一种基于深度外观的凝视估计方法。对于最具挑战性的跨数据集评估,GazeNet将最新技术水平提高了22%(从13.9度的平均误差到10.8度的平均误差)。和面部外观变化。我们显示图像分辨率和两只眼睛的使用都会影响凝视估计性能,而头部姿势和瞳孔中心信息的信息量较少。最后,我们提出了GazeNet,这是第一种基于深度外观的凝视估计方法。对于最具挑战性的跨数据集评估,GazeNet将最新技术水平提高了22%(从13.9度的平均误差到10.8度的平均误差)。和面部外观变化。我们显示图像分辨率和两只眼睛的使用都会影响凝视估计性能,而头部姿势和瞳孔中心信息的信息量较少。最后,我们提出了GazeNet,这是第一种基于深度外观的凝视估计方法。对于最具挑战性的跨数据集评估,GazeNet将最新技术水平提高了22%(从13.9度的平均误差到10.8度的平均误差)。 -
Appearance-based Gaze Estimation in the Wild, X. Zhang, Y. Sugano, M. Fritz and A. Bulling, Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June, p.4511-4520, (2015).
推荐数据集
-
多显著性对象数据集
共享本数据集共有 1224 张图像来自四个公共图像数据集:COCO、VOC07、ImageNet 和 SUN。Amazon Mechanic Turk 工作人员将每个图像标记为包含 0、1、2、3 或 4 个以上的显着对象。可以在imgIdx.mat中找到此标签信息以及边界框注释,一个存储图像信息的matlab结构数组。MSO 数据集是 SOS 数据集测试集的子集。波士顿大学的团队删除了一些显着对象严
-

森尼布鲁克心脏数据集
共享Sunnybrook心脏数据 (SCD),也称为2009 年心脏 MR 左心室分割挑战数据,由 45 幅来自混合患者和病理的电影 MRI 图像组成:健康、肥大、心力衰竭伴梗死和心力衰竭无梗死。 Classification There are four pathological groups in this data set, which were classified based on (K
-

HiEve数据集
共享数据集介绍该数据集专注于在各种人群和复杂事件中进行非常具有挑战性和现实性的以人为中心的分析任务,包括地铁上下车、碰撞、战斗和地震逃生。并且具有大规模和密集注释的标签,涵盖了以人为中心的分析中的广泛任务。Cite as:arXiv:2005.04490[cs.CV] (orarXiv:2005.04490v5[cs.CV]for this version) https://doi.org/10.48
-

NLPR
共享数据集介绍: NJU2K是一个包含 1,985 个图像对的大型 RGB-D 数据集。立体图像是从互联网和 3D 电影中收集的,而照片是由富士 W3 相机拍摄的。
