
Deepscores 数据集
订阅方案:
普通用户:¥30.00
VIP用户:¥0.00
联系客服
查看订阅方案
数据集简介:
展开
DescriptionDeepScores 数据集的目标是推进小物体识别的最新技术,并将物体识别问题置于场景理解的背景下。 DeepScores 包含高质量的乐谱图像,分为 300 0 000 张书面音乐,其中包含不同形状和大小的符号。拥有近一亿个小对象,这使得我们的数据集不仅独一无二,而且是最大的公共数据集。 DeepScores 带有用于对象分类、检测和语义分割的基本事实。因此,DeepSco
-
Deepscores 数据集简介
Description
DeepScores 数据集的目标是推进小物体识别的最新技术,并将物体识别问题置于场景理解的背景下。 DeepScores 包含高质量的乐谱图像,分为 300 0 000 张书面音乐,其中包含不同形状和大小的符号。拥有近一亿个小对象,这使得我们的数据集不仅独一无二,而且是最大的公共数据集。 DeepScores 带有用于对象分类、检测和语义分割的基本事实。因此,DeepScores 总体上对计算机视觉提出了相关挑战,超出了光学音乐识别 (OMR) 研究的范围。
The accompaning paperThe DeepScoresV2 Dataset and Benchmark for Music Object Detectionpublished at ICPR2020 can be found here:
https://digitalcollection.zhaw.ch/handle/11475/20647
A toolkit for convenient loading and inspection of the data can be found here:
https://github.com/yvan674/obb_anns
Code to train baseline models can be found here:
https://github.com/tuggeluk/mmdetection/tree/DSV2_Baseline_FasterRCNN
https://github.com/tuggeluk/DeepWatershedDetection/tree/dwd_old
Abstract
We present the DeepScores dataset with the goal of ad-
vancing the state-of-the-art in small objects recognition,
and by placing the question of object recognition in the
context of scene understanding. DeepScores contains highPapers With Code highlights trending Machine Learning research and the code to implement it.
The most popular research, guides, news and more in artificial intelligence
IEEE Xplore, delivering full text access to the world's highest quality technical literature in engineering and technology. | IEEE Xplore
Papers With Code highlights trending Machine Learning research and the code to implement it.
DeepScores contains high quality images of musical scores, partitioned into 300,000 sheets of written music that contain symbols of different shapes and sizes. For advancing the state-of-the-art in small objects recognition, and by placing the question of object recognition in the context of scene understanding.
什么是微小物体当目标距离成像系统较远时,目标的像只占场景图像中单个或几个像素,这类微小尺寸目标的形态特征就近似与一个点目标。微小物体检测的难点1、小目标的尺度过小,基于手工特征提取的算法大多利用目标周围的邻域信息表达目标2、小目标本身的特征不够明显,容易受图像噪声的干扰而最终导致无检测和漏检测。现有方法1、使用高分辨率摄像头较少成像过程中的干扰和噪声2、提取识别算法方面,有两大假设:...
1.AI-TOD航空图像数据集数据集: 在 28,036 张航拍图像中包含 8 个类别的 700,621 个对象实例。与现有航拍图像中的目标检测数据集相比,AI-TOD 中目标的平均大小约为 12.8 像素,远小于其他数据集。2.iSAID航空图像大规模数据集数据
推荐数据集
-
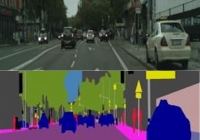
城市景观图像对数据集
共享城市景观数据(数据集主页)包含从德国驾驶的车辆中拍摄的标记视频。此版本是作为 Pix2Pix 论文的一部分创建的已处理子样本。数据集包含来自原始视频的静止图像,语义分割标签与原始图像一起显示在图像中。这是语义分割任务的最佳数据集之一。 该数据集有 2975 个训练图像文件和 500 个验证图像文件。 每个图像文件为 256x512 像素,每个文件是与图像左半部分的原始照片以及右半部分的标记图像
-

野外 3D 姿势数据集
共享数据集介绍“野外 3D 姿势数据集”是野外第一个具有准确 3D 姿势用于评估的数据集。 虽然存在户外其他数据集,但它们都仅限于较小的记录量。 3DPW 是第一个包含从移动电话摄像头拍摄的视频片段的技术。数据集包括:60 个视频序列。2D 姿势注释。使用我们的方法获得的 3D 姿势。 我们的方法利用了视频和 IMU,尽管场景很复杂,但姿势非常准确。序列中每一帧的相机姿势。3D 身体扫描和 3D 人物
-
身体部位X射线图像数据集
共享本数据集收集了来自身体各部位的X光图片。
-

非洲地区交通标志数据集
共享该数据集已特别针对非洲地区进行了改进。 两个开源数据集仅用于提取非洲地区使用的交通标志。该数据集包含来自所有类别的 76 个类,例如 监管、警告、指南和信息标志。 该数据集总共包含 19,346 张图像和每个类别至少 200 个实例。
